Privacy-Preserving Clinical NLP
Privacy-preserving Large language models for
Acronym Clinical Inference and Disambiguation
Local inference · Context-aware · On-premises deployment
Privacy-preserving Large language models for
Acronym Clinical Inference and Disambiguation
Local inference · Context-aware · On-premises deployment
Product Concepts
A snapshot of two PLACID concepts: a patient-facing mobile note translator and a reviewer-facing clinical acronym workbench.
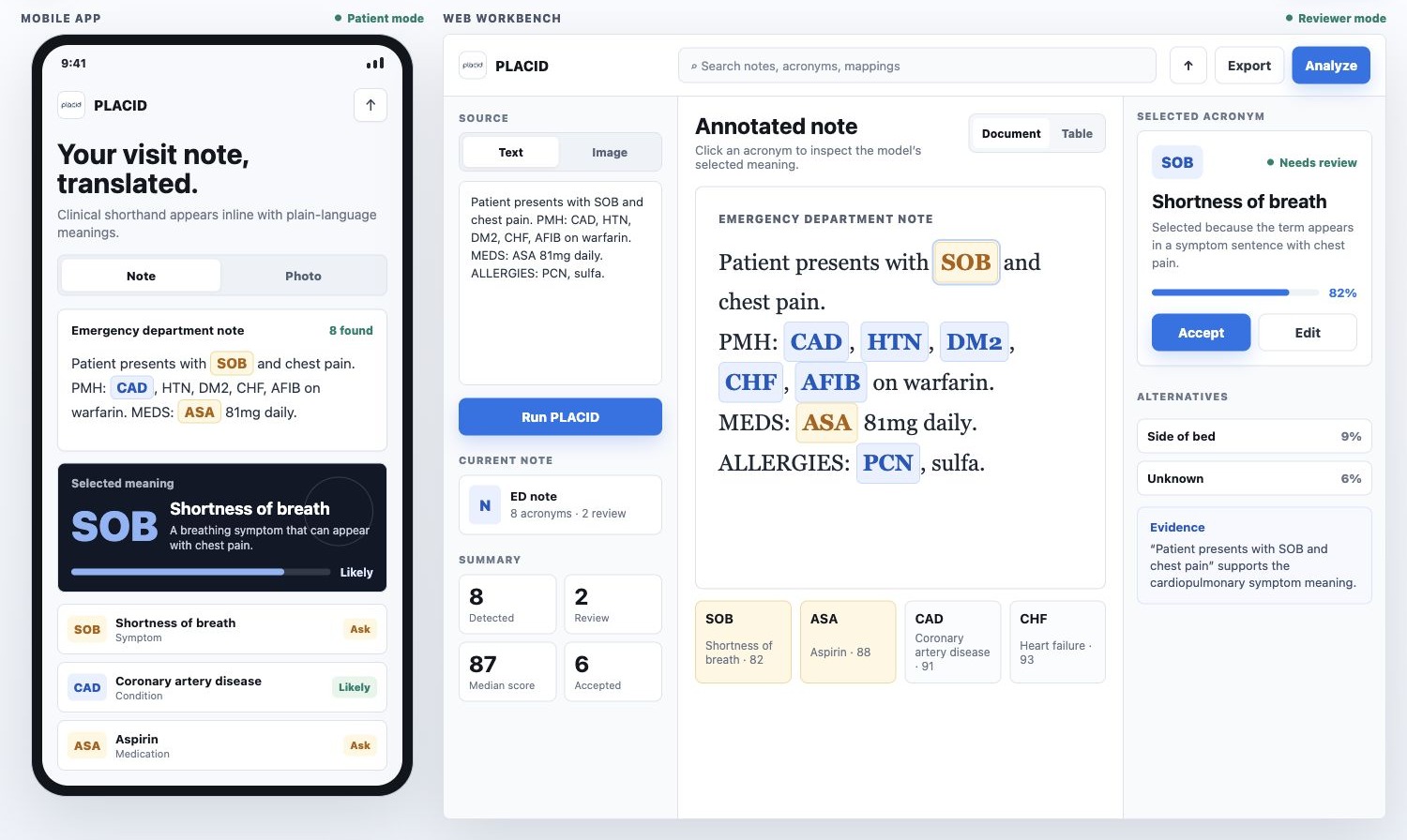
The Problem
Electronic health records contain tens of thousands of acronyms. "PT" could mean patient, physical therapy, prothrombin time, or posterior tibial, depending on context. Misinterpretation contributes to clinical errors and hinders downstream NLP tasks.
Existing solutions often require sending sensitive patient data to external APIs, creating governance and privacy barriers in healthcare. PLACID addresses both problems at once.
Acronym Ambiguity Example
Distribution depends entirely on clinical context.
Methodology
PLACID was built backwards from the constraint that no clinical text can leave the institution. Every component, from model selection through inference pipeline to evaluation harness, was chosen so the entire system can run on-premises with hospital-grade infrastructure.
Privacy is the single hardest constraint in clinical NLP. PLACID's design reflects that throughout: a model small enough to run on-prem, a context window long enough to capture the surrounding note, and an evaluation protocol built around real clinical notes rather than benchmark abstractions.
Engineering skills
Local LLM inference, prompt engineering, structured output, model quantisation.
Clinical skills
Clinical note analysis, acronym taxonomy, domain-specific evaluation.
Privacy skills
PHI handling, on-prem deployment, institutional review board alignment.
Evaluation skills
Ground-truth labelling, contextual accuracy metrics, comparative model studies.
At a glance
The pipeline is deliberately compact so it can sit inside the institution's existing infrastructure without bespoke hardware procurement.
On-prem
Deployment
Local
Inference
PHI-safe
By design
01 Survey
Mapped the space of clinical acronyms and their expansions across specialties, identifying which acronyms are ambiguous and which are stable.
02 Select
Evaluated multiple open-weight LLMs against the privacy constraint, weighing accuracy against memory footprint and inference time on hospital-spec hardware.
03 Prompt
Designed prompts that supply the surrounding clinical note as context, so the model can disambiguate based on the same signals a clinician would use.
Accuracy
04 Validate
Benchmarked PLACID against ground-truth labels from clinical experts, with per-acronym accuracy reported by specialty and acronym frequency.
On-prem
05 Deploy
Packaged for on-premises deployment with no external API calls. PHI stays inside the institutional perimeter at every stage of inference.
The System
01 · Local Inference
PLACID runs entirely on-premises. There are no external API calls and no data sharing with third-party providers — the same constraint clinical IT teams apply to every other PHI-handling system.
This privacy constraint shaped the system architecture: open-weight LLM selection, calibration for available hospital hardware, and the structure of the inference pipeline all followed from the deployment environment.
02 · Context-aware
PLACID disambiguates by looking at the surrounding clinical context, the same signal a clinician uses. "PT" in an orthopaedics discharge note rarely means prothrombin time; in a haematology lab report it almost always does.
The output is a probability distribution over candidate expansions rather than a single guess, so downstream systems and clinicians both have visibility into how confident the model is.
03 · Structured output
Every disambiguation is returned as a structured record — the original token, the expanded meaning, the confidence score, and the context window the model used. Downstream NLP tools can query it programmatically, and clinical reviewers can read it directly.
This structure is what makes PLACID composable. Other clinical pipelines can call it as a service without having to handle free-text parsing.
Web Stack
PLACID is designed as a deployable web application with the LLM embedded into the institutional stack. The browser workbench sends de-identified note text to a local inference service, receives structured acronym mappings, and renders confidence, alternatives, and evidence without clinical text leaving the hospital network.
The same local model service can support the reviewer workbench, patient-facing translation views, and downstream NLP pipelines through a consistent JSON contract.
Front end
Browser-based note review, acronym highlighting, evidence panels, confidence meters, and accept/edit workflows.
LLM layer
Open-weight LLM inference runs locally/on-prem, tuned for acronym expansion with surrounding note context.
Service contract
Returns acronym, expansion, confidence, alternatives, and context evidence for auditing and downstream reuse.
Deployment
Packaged for hospital infrastructure so PHI stays inside the institutional perimeter throughout inference.
Why It Matters
On-prem
Deployment model
Context
Disambiguation signal
JSON
Composable output
Active
Project status